Designing your events
Event structure
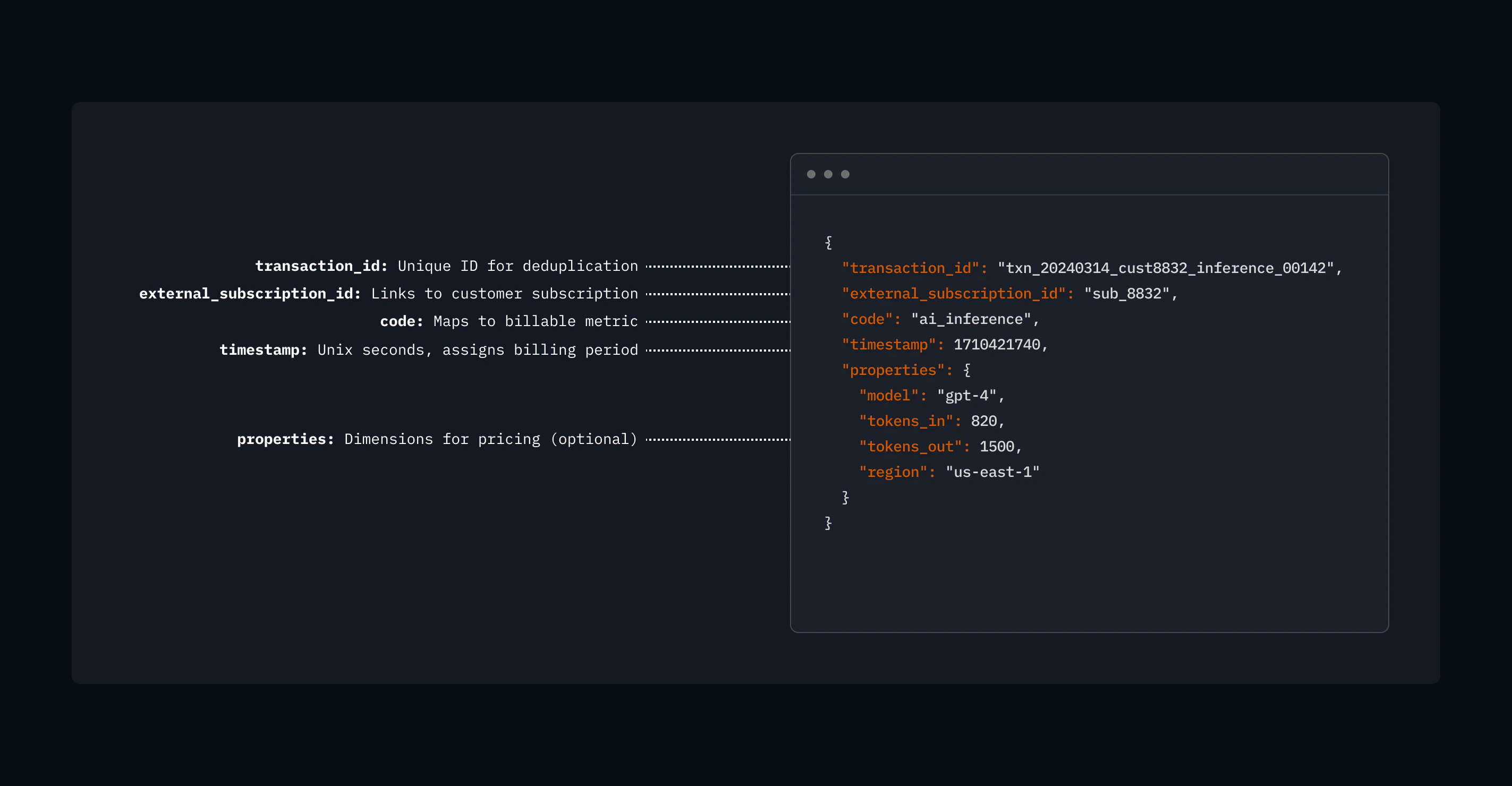
Event schema
transaction_id (required)
transaction_id (required)
A unique ID you generate. Lago uses it for deduplication: if the same event arrives twice, only the first is billed.
external_subscription_id (required)
external_subscription_id (required)
Ties the event to a customer subscription. This is how Lago knows which pricing plan to apply.
If the
external_subscription_id does not match an active subscription in Lago, the event is ingested but not post-processed.code (required)
code (required)
Maps to a billable metric you’ve defined in Lago (e.g.,
ai_inference, api_calls, storage_gb). Treat the code as a stable API contract between your application and your billing configuration.
If the code does not match a billable metric in Lago, the event is ingested but not post-processed.timestamp (optional)
timestamp (optional)
When the event happened, as a Unix timestamp. Lago uses this to assign the event to the correct billing period.We typically log events using timestamps in seconds, such as
1741219251. When higher precision is required, you can use millisecond accuracy in the format 1741219251.590, where the dot acts as the decimal separator.If you do not specify a timestamp, Lago automatically uses the reception time of the event.
properties (optional)
properties (optional)
Key-value pairs carrying the data your pricing needs: token counts, regions, instance types, anything you price on. Properties can be any JSON supported datatype including
strings, integers, floats, uuids, or timestamps.Lago ignores properties that don’t match a billable metric, so include dimensions you might price on in the future — extra fields cost nothing but give you pricing flexibility later.Events sent to a UNIQUE COUNT billable metric accept an operation_type property to control whether the unique value is added to or removed from the count:add: Adds the unique value. Optional: Lago adds by default ifoperation_typeis omitted.remove: Removes the unique value from the count. Required whenever you want to explicitly remove a unit.
precise_total_amount_cents (optional)
precise_total_amount_cents (optional)
Skip Lago’s aggregation and set the monetary amount directly. This value must be a string to avoid floating-point rounding issues.If not specified, Lago sets it to 0 and the event is not included in charge aggregation for dynamic charge models.
Use cases in detail
- AI / LLM
- Cloud / GPU
- Fintech
- API Platform
- Storage / CDN
- Marketplace
Billing model: Per-token pricing, rates vary by model and sometimes by input vs. output tokens.Event design: One event per inference request. Properties carry Billable metric setup: Create a metric
model, tokens_in, tokens_out, and any other dimensions you price on.llm_tokens with aggregation type SUM and a custom expression like properties.tokens_in + properties.tokens_out. Use model as a charge filter to apply different per-token rates for GPT-4, GPT-3.5, Claude, etc.Volume consideration: A busy AI platform might generate thousands of inference events per second. At low volume, send every event via REST API. At high volume, stream through Kafka or pre-aggregate to one event per customer per model per hour.Event design best practices
Send more data than you need today
Properties are flexible: include dimensions you might price on in the future. Lago ignores properties that don’t match a billable metric, so extra fields cost nothing but give you pricing flexibility later.
Make transaction_id meaningful
Don’t use random UUIDs. Embed the customer, event type, and timestamp so you can trace a billed amount back to its source event without guessing.
One event per billable action
If a customer makes 3 API calls, send 3 events, not 1 event with a count of 3. This gives you maximum flexibility. The exception is pre-aggregation at very high volumes.
Use timestamp accurately
Lago assigns events to billing periods based on
timestamp, not arrival time. Late-arriving events are placed in the correct historical period. This matters for reconciliation and billing accuracy.Treat code as a contract
The
code ties your event to a billable metric. If you rename a metric, you need to update the code in your events. Treat it as a stable API contract.Test with a single event first
Send one event via the REST API and verify it appears in
GET /events/{transaction_id} before scaling to batch or streaming delivery.Delivery methods
Lago accepts events through multiple channels. All methods use the same event schema and produce identical billing results.
For the full list of available ingestion sources, see Metering ingestion sources.
REST API
Replace
__LAGO_API_URL__ with api.getlago.com or api.eu.getlago.com for Lago Cloud, or your own instance URL for self-hosted deployments.- Single event
- Batch (up to 100)
Client libraries
Agent SDK
For applications that bill on LLM tokens, the Agent SDK is the lowest-effort path to ingestion. You wrap your existing provider client and keep calling it the same way. The SDK extracts token usage from each response, normalizes it across providers, and ships events to Lago in the background.- Providers: AWS Bedrock (
ConverseandInvokeModel, sync and stream), Mistral, OpenAI, Anthropic, Google Gemini, and potentially more. - Languages: Python and JavaScript / TypeScript).
Kafka / Redpanda configuration
Kafka ingestion requires the ClickHouse event store (see Architecture section above).Lago Cloud
Lago Cloud
Lago Cloud includes a managed Kafka endpoint. Contact the team for your connection details (broker address, credentials, topic name). No infrastructure to deploy.
Reader / producer tuning
Reader / producer tuning
Lago can directly consume events from your Kafka topic (which will require opening access to your Kafka broker / topic). Alternatively, you can send your events to a dedicated topic on our infrastructure (AWS VPC Peering or PrivateLink).In this second case, these settings have the biggest impact on throughput:
Partition count: Aim for partition count >= number of event processor instances. More partitions = more consumer parallelism.
Redpanda on Kubernetes (self-hosted)
Redpanda on Kubernetes (self-hosted)
Minimal production deployment:See Redpanda Operator docs for TLS, rack awareness, and tiered storage.
ClickHouse on Kubernetes documentation is coming soon.
Amazon Kinesis configuration
Kinesis setup
Kinesis setup
We can read events directly from your Kinesis stream. We’ll need:
- Kinesis Stream ARN
- Credentials:
- Role ARN to assume, or
- IAM Access Keys
Amazon S3 configuration
File format
File format
Newline-delimited JSON (
.jsonl or .jsonl.gz). Target 100MB-1GB per compressed file.Idempotent: Re-running an import after failure is always safe (dedup by
transaction_id).S3 setup
S3 setup
We generally provide an S3 bucket on our infrastructure where you can deliver your files, along with credentials to upload new files.If you prefer to provide your own S3 bucket, an SQS queue is required to capture new file uploads (configurable on the S3 bucket properties/notifications). We would need:
- S3 bucket
- S3 Region
- SQS URL
- Credentials:
- Role ARN to assume, or
- IAM Access Keys
Idempotency and deduplication
Lago guarantees exactly-once processing through thetransaction_id:
- Same
transaction_id+external_subscription_idarrives twice → only the first is billed. - Works across delivery methods: a REST event won’t be billed again if the same ID arrives via Kafka.
- Retries are always safe. REST timeout? Resend. Kafka consumer restart? Reprocess. S3 import interrupted? Re-trigger.
Handling edge cases
Late-arriving events
Late-arriving events
Events that arrive after a billing period has closed are assigned to the correct historical period based on
timestamp. If the invoice has already been finalized, the event will not be included in the billing cycle. However if they match a recurring billable metric, they will impact the next billing cycle.Correcting events
Correcting events
- With Postgres: duplicates are rejected with 422 (no replacement). Use a new
transaction_idto correct. - With ClickHouse: to amend a previously sent event, send a new event with the same
transaction_idandtimestampwith the updated properties. The new event replaces the original.
Events before subscription start
Events before subscription start
Events with a
timestamp before the subscription’s started_at date are ingested, but ignored during post-processing and aggregation. Validate your timestamps if you’re backfilling historical data.Events for terminated subscriptions
Events for terminated subscriptions
Events for subscriptions that have been terminated are ingested, but ignored during post-processing. This is a safety mechanism — you don’t need to stop your event pipeline the instant a subscription ends.
You can still send usage events with timestamp before the subscription
terminated_at if you want to amend a draft invoice.Verifying your integration
Test with a single event first. Send one event via the REST API, then retrieve it withGET /events/{transaction_id} to confirm Lago received and parsed it correctly.
Reconciliation pattern: Compare your source-of-truth event count against Lago. Use GET /events filtered by external_subscription_id, timestamp_from, and timestamp_to, then compare against your internal logs. Any delta means dropped events or events that failed validation.
What to watch on your side:
- REST API response codes:
200= accepted,422= validation error (bad schema, unknown subscription),429= rate limited (retry safely),5xx= server-side error (investigate before retrying) - At invoice time: compare line item quantities against your own event counts per subscription per billing period. If they diverge, check for late arrivals outside the billing window.
Rate limits
Lago enforces per-organization rate limits on the REST API, with the highest limits on event ingestion. If you exceed them you receive a429 Too Many Requests response with X-RateLimit-Limit, X-RateLimit-Remaining, and X-RateLimit-Reset headers. Retrying after a 429 is safe thanks to transaction_id deduplication. See Rate limits for the full limits and retry guidance.
Kafka, Kinesis, and S3 connectors are not subject to REST API rate limits. Their throughput is bounded by your broker or infrastructure capacity.